목표 :
Pandas 패키지 라이브러리를 사용한,
Python 데이터 분석
1. series
Pandas패키지에서는 series라는 리스트를 사용한다.
딕셔너리, 리스트로 시리즈를 만들 수 있다.
|
dic = {'a':1,'b':2,'c':3}
dic_series = pd.Series(dic)
dic_series
|
ls = [1,2,3]
ls_series = pd.Series(ls, index=['a','b','c'])
# index를 사용하지 않으면 0부터 인덱스가 부여된다 |
|
a 1
b 2 c 3 |
a 1
b 2 c 3 |
2. Dataframe
Series를 이어붙여서 표로 만든 것을 Dataframe 이라고 한다.
딕셔너리, 리스트로 시리즈를 만들 수 있다.
| 딕셔너리로 만들기 | 리스트로 만들기 | 시리즈를 결합해서 만들기 |
| 열 단위로 값을 입력할 때 이용 값의 길이가 반드시 모두 같아야 한다. |
행 단위로 값을 입력할 떄 이용 각 리스트의 길이가 같지 않으면 에러가 난다. |
시리즈들을 각각 만들어서 각 시리즈들에 컬럼 이름을 붙여서 DataFrame으로 묶음 |
|
import pandas as pd
dic = {'Name':['John','Merry','Chris']
, 'Number':[1,2,3]
, 'Month':['Feb','Oct','Nov']}
df = pd.DataFrame(dic)
df
|
ls = [['John', 1, 'Feb']
,['Merry',2,'Oct']
,['Chris',3,'Nov']]
df = pd.DataFrame(ls, columns=['Name','Number','Month'])
df
|
name_series = pd.Series(['John','Merry','Chris'])
number_series = pd.Series([1,2,3])
month_series = pd.Series(['Feb','Oct','Nov'])
df = pd.DataFrame({'Name':name_series, 'Number':number_series, 'Month':month_series})
|
|
Name Number Month
0 John 1 Feb 1 Merry 2 Oct 2 Chris 3 Nov |
Name Number Month
0 John 1 Feb 1 Merry 2 Oct 2 Chris 3 Nov |
Name Number Month
0 John 1 Feb 1 Merry 2 Oct 2 Chris 3 Nov |
3. 데이터 프레임 관련 기본 함수
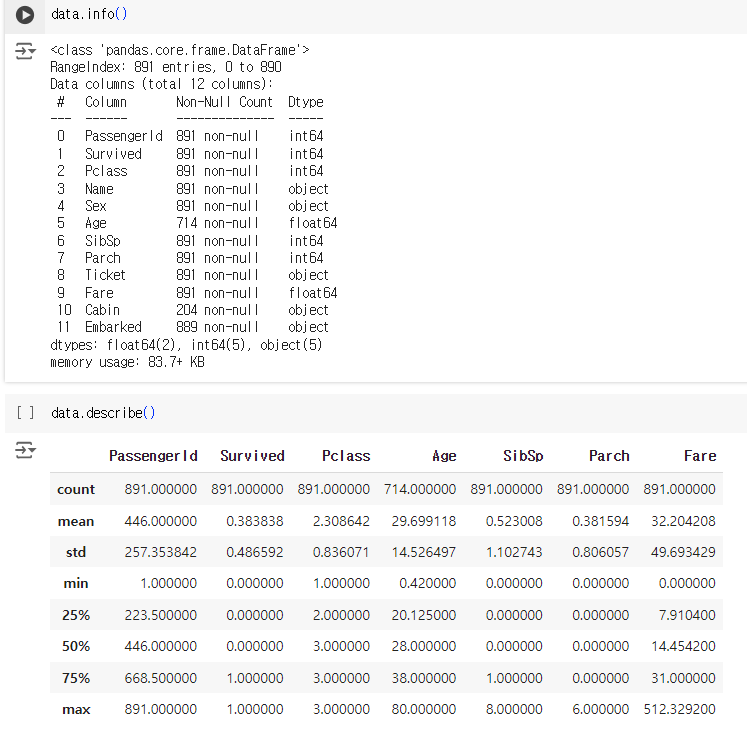
data = pd.read_csv('path')
data. head(n) #데이터프레임의 처음부터 n행을 보여준다. 기본은 5
data. tail(n) #데이터프레임의 마지막부터 n행을 보여준다. 기본은 5

data. info(): 전체 행의 갯수, 컬럼 정보, 결측치, 데이터 타입을 보여줍니다.
data. describe(): 컬럼별 값의 갯수, 평균, 표준편차, 최솟값, 최댓값, 사분위수를 보여줍니다.
4. 행열 조회
| 행 | 데이터프레임명[인덱스:인덱스+1] 데이터프레임명[시작인덱스:끝인덱스+1] |
df[:10] # 0~9번 인덱스 출력
df[3:7] # 3~6번 인덱스 출력
|
| 열 | 데이터프레임[컬럼명] 데이터프레임.컬럼명 데이터프레임[[컬럼명1, 컬럼명2, ...]] 데이터프레임[컬럼명].to_frame() 데이터프레임[ [컬럼명] ] |
df['Survived']
df.Survived #둘은 같은 결과
df[['Survived','Pclass','Name']]
df['Survived'].to_frame()
df[['Survived']] #두개는 데이터프레임 형식으로 출력
|
| loc | 레이블 값을 사용해서 조회 데이터프레임명.loc[행조건,열조건] 열만 조회할때는 행조건에 :를 입력 |
df.loc[3,] #3번째 행 아님, 인덱스가 3번인 행 갖고옴,
#그러니까 인덱스의 값이랑 대조해서 일치하는것을 불러옴 df.loc[:,'Name'] #열만 조회할때는 행조건에 :를 입력합니다
df.loc[3:5,] #3번부터 5번 행을 출력
|
| iloc | 위치 인덱스를 사용해서 조회 데이터프레임명.iloc[행인덱스조건,열인덱스조건] |
df1.iloc[3,] #3번째 행 반환. Name이 인덱스임에도 3으로 호출 가능
df1.iloc[3:7,2:4] #3~6번째 행, 2~3번 열 출력
|
ioc의 경우, 아래와 같은 방법으로 인덱스 값을 설정할 수 있다.
df1 = df.set_index('Name') #Name열을 인덱스로 설정
df1.loc['Heikkinen, Miss. Laina',] #새로 설정한 인덱스에서 Heikkinen, Miss. Laina 값을 가지는 열 호출
df1.loc[3:5,] #이 경우엔 인덱스가 숫자가 아니므로 이 코드는 실행이 안된다
5. 데이터 추출
| 정렬 | 데이터프레임명.sort_values(정렬기준컬럼) |
df.sort_values('Age') #나이를 기준으로 정렬
df.sort_values('Age', ascending=False) #내림차순
df.sort_values(['Age','Fare'], ascending=[False,True])
|
| 추출 | 데이터프레임명[조건식] 데이터프레임명.query('조건식') 조건식이 True인 행들을 출력 데이터프레임명[조건식] .isin( 값 ) |
df[df['Pclass'] == 1]
df.query('Pclass == 1')
df[(df['Pclass'] == 1) & (df['Age'] >= 30)]
df.query('Pclass == 1 and Age >= 30')
df[df['PassengerId'].isin([3,100,500])]
df.query('PassengerId.isin([3,100,500])')
|
'Python' 카테고리의 다른 글
| dataframe 3 - 데이터 가공 (1) | 2024.07.05 |
|---|---|
| dataframe 2 - 구조 (0) | 2024.07.05 |
| 파이썬 기초 5- 라이브러리 (0) | 2024.07.05 |
| 파이썬 기초 4 - 함수와 예외처리 (0) | 2024.07.05 |
| 파이썬 기초 3 - Comprehenshion (0) | 2024.07.05 |